
Société Générale : comment faire passer à l’échelle ses outils de machine learning grâce à Azure ?

 Temps de lecture : 5 minutes
Temps de lecture : 5 minutes
Publié le 7 novembre 2019
Scanner 800 000 pages de documents en seulement deux heures. En extraire des informations réglementaires. Le tout, sans erreur, grâce au machine learning. C’est ce qu’a réalisé le Lab IA de Société Générale en 2018. Récit.
À l’automne 2018, la division Global Banking & Investor Solutions de Société Générale (GBIS), spécialisée dans les grands comptes, doit répondre à une nouvelle exigence réglementaire : répertorier dans les systèmes informatiques des clauses juridiques sur les programmes d’émission de titres.
Les systèmes informatiques permettent déjà de réaliser ce travail sur tous les nouveaux documents. Mais il s’agissait également de traiter les documents déjà présents dans la base. Soit 70 000 documents de 10 à 15 pages, dont il faut extraire des informations à insérer dans les systèmes. Bilan du projet avec Guillaume Fournier, co-head de l’équipe Data Science au sein de la division Wholesale du groupe Société Générale.


La reconnaissance de texte : un savoir essentiel pour Société Générale
Guillaume Fournier a constitué son équipe en 2016. Le Lab IA compte une dizaine de data scientists, mais aussi deux data engineers. Ces derniers développent pour les clients et les équipes de la banque des applications et des services innovants. Tous disponibles sur la plateforme SG Markets, l’écosystème digital dédié aux activités B to B de la banque.
Depuis la création du Lab, de nombreux cas d’usage ont été développés. Notamment, des outils de recommandation de produits d’investissements pour les clients et d’aide à la vente pour les équipes commerciales. Avec l’expérience des projets réalisés les équipes sont aujourd’hui capables de les répliquer facilement sur des projets ayant des enjeux similaires.
Les projets passent tous par une phase de sélection par la valeur pour développer rapidement des Minimum Viable Products (MVP). Le process de développement très court permet de tester des innovations et d’abandonner rapidement un projet qui ne prouverait pas sa valeur. « Nous avons récemment travaillé sur de nombreux projets en lien avec du traitement de documents. En effet, ces derniers sont encore souvent traités à la main. Cela est non seulement très chronophage pour les collaborateurs, mais parfois source d’erreurs, et donc de risques opérationnels. Pour mener ces projets, un outil indispensable est le service d’OCR (optical character recognition). Il permet de transformer un document scanné en texte », explique Guillaume Fournier.
« Nous avons une stratégie de développement de produits sous forme d’APIs. Pour réaliser nos projets, nous prenons des API tierces – comme celles d’Azure – d’un côté et nos API d’IA de l’autre. Nous les connectons ensuite pour réaliser de nouveaux use cases. C’est une solution extrêmement simple à mettre en œuvre, » précise Guillaume Fournier.
Le choix des services cognitifs OCR
Société Générale a déjà développé plusieurs projets sur le cloud hybride (privé et public) Azure. En cet automne 2018, les équipes disposaient donc de peu de temps pour répondre aux exigences d’un nouveau projet réglementaire. Pour cela, il leur fallait traiter 70 000 documents comptant chacun entre 10 et 15 pages. Ces derniers étaient rédigés dans trois langues différentes et leur modèle changeait tous les deux ans. Il s’agissait alors d’un projet orienté « reprise de stock ». C’est-à-dire qu’il fallait appliquer un traitement à l’ensemble des documents déjà présents dans le système d’information, afin d’en extraire une liste de clauses juridiques.
Pour cela, nous avons choisi le service cognitif OCR d’Azure. Ces outils sont assez standardisés, nous n’avions pas intérêt à les redévelopper chez nous.
Le service OCR transforme les documents en textes, qui sont ensuite traités par les algorithmes de Société Générale. L’algorithme fonctionne par blocs et non de manière linéaire. L’objectif est de déterminer si un bloc contient un certain type de données, et d’en extraire les informations importantes. Un modèle qui s’avère efficace même avec un jeu de données réduit.
En effet, le Lab a étiqueté une vingtaine de documents dans un premier temps, afin de réaliser un premier entraînement de l’algorithme. La seconde étape a consisté à scanner 200 documents, d’y appliquer l’algorithme puis de corriger les erreurs, ce qui a permis de le faire progresser jusqu’à un taux de fiabilité de 99 %. L’algorithme a alors pu scanner les 70 000 documents de ce lot, en toute confiance.
« La solution est basée sur des caractéristiques de texte standards (paquets de mots, n‑grams, ). Il est possible d’y ajouter des caractéristiques sur mesure comme la “détection du texte autour du bloc”, la présence de dates et nombres, etc. Ce sont ces caractéristiques qui aident l’algorithme à avoir de bons résultats avec un nombre limité de documents. Nous utilisons ensuite un modèle à base d’arbre décisionnel du type de LightGBM », précise Lionel Massoulard, Data Scientist au sein de GBIS.
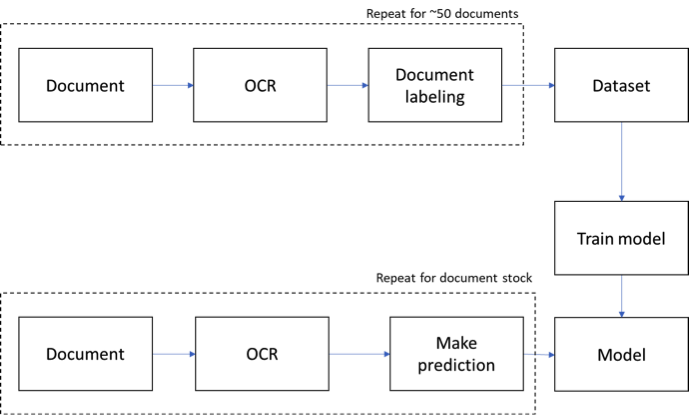
Schéma du process d’entraînement de l’algorithme
Le cloud Azure, une solution efficace et scalable
Reposant sur le cloud public, les solutions Azure permettent de supporter des pics de charge très importants, le système de traitement par lot Azure Batch permet aux solutions développées de monter en charge sur plusieurs milliers de core. La facturation s’effectue à l’usage : à l’appel d’API pour les services cognitifs et aux heures de calculs consommées pour Azure Batch.
Azure nous a permis de bénéficier d’une solution scalable à un coût réduit, poursuit Guillaume Fournier. C’est idéal pour un besoin ponctuel tel que celui que nous avions, car nous avons pu bénéficier de capacité de calculs très importantes sans investir dans des infrastructures, qui sont coûteuses sur le long terme.
Et d’ajouter « Grâce à Azure Batch, qui permet d’ordonnancer des tâches de calcul, l’analyse a pu être intégralement réalisée en seulement deux heures. Le quota d’appel aux API était de 100 par seconde. Nous avons donc décidé de solliciter 400 cores en parallèle (100*DS3v2 instances). Nous avons choisi de remplir le quota d’appels proposé par Azure au maximum pour aller très vite. C’est une scalabilité qui ne coûte pas plus cher. ».
Notre processus de traitement fonctionne ainsi : envoi du document sur le cloud Azure, transformation des PDFs en images, transformation des images en texte à l’aide de l’API d’OCR et récupération des données transformées depuis le cloud Azure.
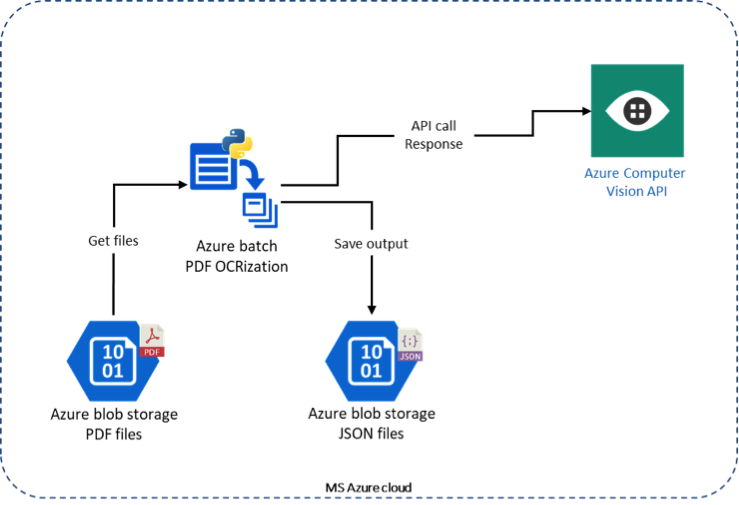
Le fonctionnement de la transformation de documents à l’aide d’Azure Batch
Des garanties de sécurité
« Nos équipes IT sécurité ont garanti que la solution opérée dans le cloud public correspondait à nos exigences, précise Guillaume Fournier. Nous avons en réalité recréé une infrastructure Société Générale dans le cloud public, qui était fermée depuis l’extérieur et accessible uniquement par Société Générale. Azure offre les garanties à la sécurisation de ce que l’on peut faire dans le cloud public. À nous de le mettre en œuvre, selon nos propres règles. »
Certains projets ne peuvent pas, pour des raisons réglementaires et de sécurité, être développés sur le cloud public. Dans ces cas-là, nous choisissons une solution interne, mais cela ne nous offre pas la même scalabilité. Cela ne convient donc qu’aux projets impliquant le traitement de données sensibles, notamment celles de nos clients. Dans les mois à venir, nous envisageons de mettre en production une quinzaine de cas d’usage supplémentaires nécessitant ces technologies et tirant bénéfice du cloud Azure.
Retrouvez les formations à ces technologies Azure, disponibles en ligne gratuitement :
- Se former à extraire du texte imprimé (OCR) grâce à l’API REST